



The CrowdStrike crash lesson every dev should remember
What a small, yet devastating bug can teach us about effective software development

On July 19, we saw what might have been the largest IT outage in history.
8.5 million Windows devices crashed and were unable to boot up. This crash affected everything from flights to university classes to surgeries. Even Times Square was illuminated with the ghostly blue of the "Blue Screen of Death" on its big screens.
The outage wasn't a cybersecurity issue, as was initially suspected. However, it was caused by an update to the cybersecurity software, CrowdStrike. Unfortunately, this update contained some bad code.
Today, I'll break down exactly what happened with the CrowdStrike crash, and why it serves as a warning for developers and companies alike:
The consequences of bad code
Why CrowdStrike's code caused crashes
How we can prevent this from happening again
Let's get started.
The consequences of bad code
In cybersecurity, we use terms like bad actors and malicious code when we're talking about individuals and code with the intent to harm users. But when we say bad code, what we simply mean is that the code had a bug.
Bugs come from various sources. They can be logic errors, syntax errors, semantic errors, etc. They can lead to programs crashing, or otherwise unexpected results. The particular bug that led to the CrowdStrike crash involved a logic error.

The bad code in the July 19 update was in a particular configuration file. A configuration file is basically a set of instructions that tells the software what to do in certain scenarios. For CrowdStrike's update, the configuration file contained new information intended to protect from new threats. Unfortunately, it instead caused CrowdStrike to crash — along with the devices on which it was installed.
Why CrowdStrike's code caused crashes
We've all had programs crash on our computers, and it usually doesn't take the whole computer down with it. So why would CrowdStrike's crash cause an entire device to fail?
The short answer is the type of permissions that security software like CrowdStrike. We can visualize CrowdStrike's permissions on the protection ring.
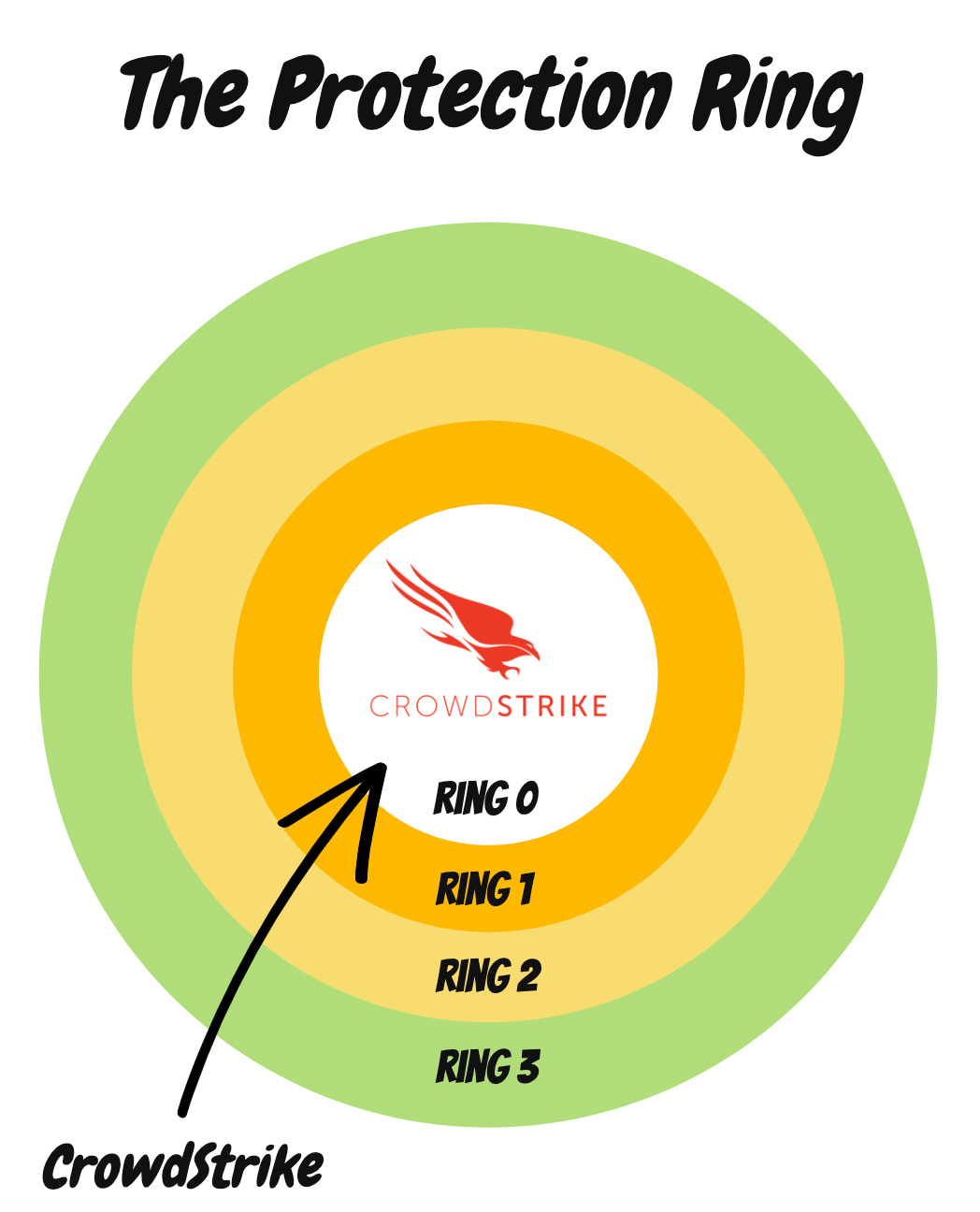
The protection ring determines the level of control a program has over a device's CPU (Core Processing Unit). The CPU is like the heart of a computer. Programs that run in Ring 0 have the greatest access to CPU, while programs in Ring 3 have the least access.
If a program running in Ring 3 were to fail, it wouldn't impact the rest of the system. However, a failure in a program running in Ring 0 can take down the entire device. This is exactly what happened when CrowdStrike's bug occurred.
Cybersecurity software like CrowdStrike has to run in Ring 0. This is because the protective software needs to be active before any other processes start. If not, malicious code could take over before the software can stop it. Unfortunately, millions of Windows devices simply couldn't boot up because of CrowdStrike's crash.
How we can prevent this from happening again
Bugs are inevitable. That's why debugging is an essential skill. However, it isn't failproof, and debugging alone is not enough to prevent bugs from happening.
The good news is that there are several well-established best practices that can catch and resolve bugs. Most organizations implement these practices. (As you may expect, there has been some question as to whether CrowdStrike has been implementing them, and I'll get to that in a moment.)
Before discussing those practices, let's take a look at the software development life cycle (SDLC).

If you're not familiar with it, SDLC is a plan that organizations follow to develop and maintain their software. Leadership can coordinate everything from new software to updates using the roadmap outlined by the SDLC. The SDLC is not only designed around efficiency and effective solutions, but also around the goal of yielding high quality software. The tasks that really begin to target bugs are seen in the later stretch of the SDLC cycle, once the building has begun.
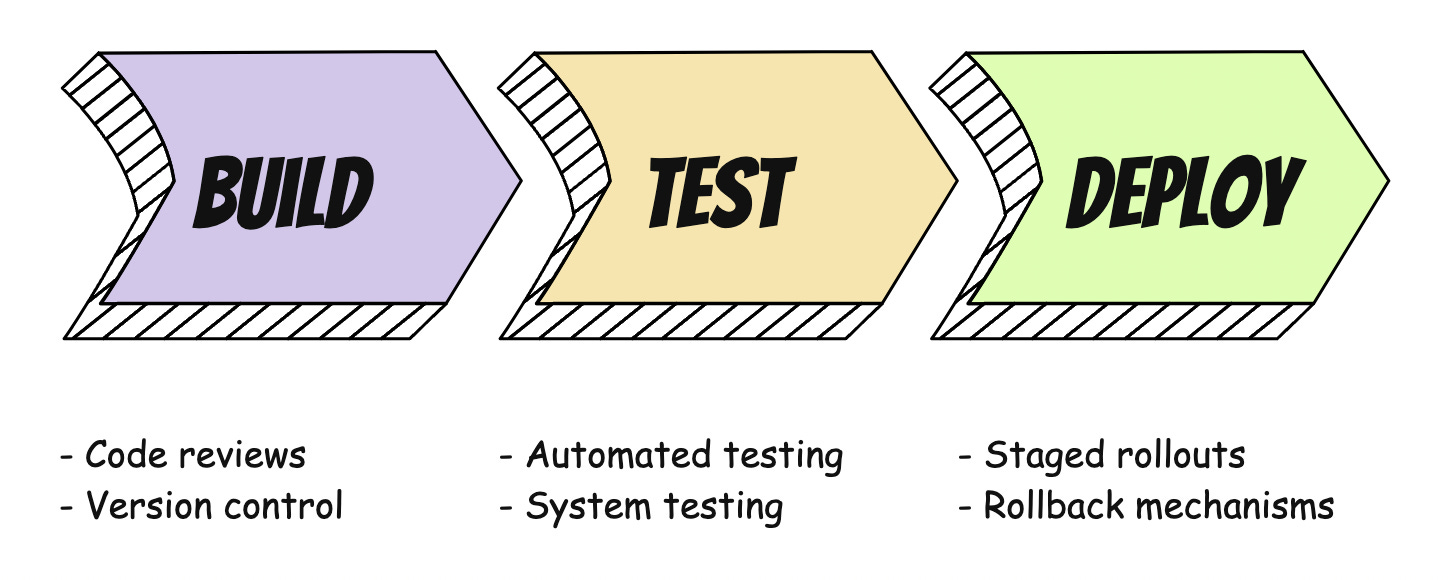
Some of the most helpful practices for spotting and resolving bugs are found in the Build, Test, and Deploy phases. These include:
Code reviews: Developers review code to catch errors and inconsistencies
Version control: Keeping a log of recent changes and previous versions
Testing: Ensuring the software works in different situations
Staged rollouts: Releasing software or updates in stages, instead of all at once
Rollback mechanisms: The ability to undo changes and revert to previous versions of software, if needed
Some of these practices help catch bugs before they are sent out to users. However, that's not always possible. No matter how rigorous we are, some bugs can slip past safeguards, or will happen in unexpected scenarios we haven't tested for. When that happens, practices such as staged rollouts and rollback mechanisms help us bounce back with minimal impact on users.
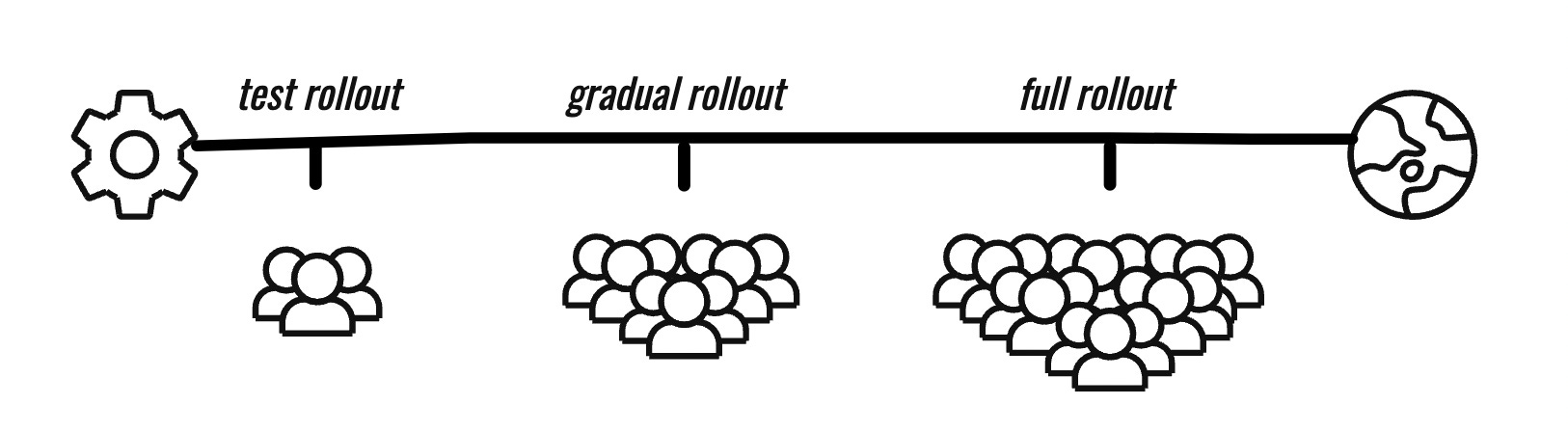
There has been significant concern about how closely CrowdStrike has been adhering to these best practices. For instance, it's clear that CrowdStrike did not implement staged rollouts. Staging rollouts means we release an update gradually, starting from a small portion of users and ending with every user. This gradual release would help us become aware of any bugs in an early stage, at which point we would stop releasing the update to more users. If CrowdStrike had staged rollouts, they would have known the update was crashing Windows devices earlier, and stopped before it affected 8.5 million users.
Unfortunately CrowdStrike didn't adhere fully to several best practices, and this outage is a grave demonstration of the consequences of ignoring these tried-and-true safety measures.
What CrowdStrike teaches us about software development
In a world that depends on technology, developers and organizations have a huge responsibility to ensure their software is as good as it can be. This doesn't mean we have to achieve perfection. Mistakes are inevitable. But we can prevent major mistakes such as the CrowdStrike bug by adhering to all these standards at an individual and organizational level.
When it comes to ensuring software quality, you will likely work with other specialists like DevOps engineers. But even if you do, certain key tasks will always be your responsibility. These include code reviews, writing tests, and following the coding best practices and guidance within your organization.
Every software development practice has a good reason behind it. While they may seem tedious, don't take them for granted. Your team, your software's users, and the world will be counting on you!
Happy learning!